Tracking down strange out of memory errors in AWS Batch
Recently, one of my colleagues came to me with a mysterious problem they were having with one of our production tasks running on AWS Batch. This particular task would be launched based on user interaction in a internal web application and run a fairly hefty machine learning model in docker container. Recently, this job started failing, not all the time, but sometimes on larger input files the job would fail with an out of memory error. My colleague came to me because they could run the same Docker container on their local machine without error so it seemed like an issue specific to the production environment.
To understand a little about AWS Batch: you create Docker containers and then specify a “job definition” that holds additional information about how to run that container, such as the amount of RAM, number of CPUs, environment variables, etc. This information can be overridden on a per job basis as well, which makes the system flexible in cases where there is a much large dataset to process. The jobs themselves are for batch processing, like taking input files and performing complex and timer consuming transformations on them. Jobs get submitted to a queue and the AWS Batch scheduler will attempt to pack as many of the containers onto one instance to minimize the amount of left over resources.
First up, I confirmed that the code did run without issue on an ec2 machine. And I got intrigued by the mystery because the ec2 machine definitely had less memory than the Batch job was set up to use. So why was the production job failing?
Okay, so how about just upping the memory in the Batch job? Can we just push this through to unblock our customers. By default, we run the production job with 64Gb of RAM, so I tried 128, 256, 512 Gb of memory… Nope, out of memory. Now there is no way that this job could be using that much RAM and no way that there is that much difference between running it on an ec2 and Batch (I mean, there should be none).
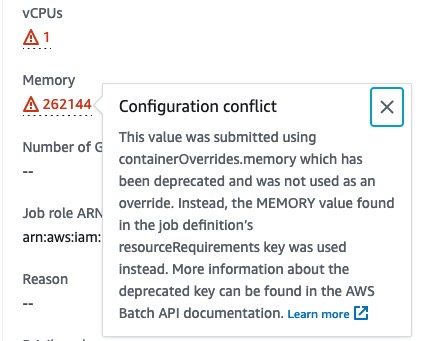
I looked at the ec2 dashboard and found that the instance trying to run the job was way smaller than expected, in fact it only had a 2 Gb of RAM. Wait, what. How come the instance that Batch launched was way smaller than the one that it would need to run the job. To double check I went back into the AWS Batch console, clicked on the individual job details and then strolled down to the container limit section. There I saw a helpful little exclamation mark saying that the way we passed in container overrides had been depreciated and that it was falling back to default values.
And so the mystery was revealed, the large RAM values weren’t ever being taken into account. It would have been nice if these jobs failed straight away instead of silently being accepted in a corrupted state.